Posts Tagged ‘FireStream’
تحول در دنیای شبیه سازی های علمی
اگر بخاطر داشته باشید، تا همین چند سال اخیر، سرعت Clock پردازنده ها، همواره از قانون مور طبعیت میکردند و ظرف هر ۱۸ ماه یکبار سرعت آنها به ۲ برابر رشد میافت. اما به یک باره تب این گریز سرعت فروکش کرد و سرعت بیشتر پردازنده ها، دیگر در Clock ماکزیمم آنها بیان نمیشد، بلکه R&D شرکت ها بر سرحد مساله ی پردازش موازی به رسیده بودند و این یعنی که عملکرد CPU ها صرفا با سرعت بیشینه بیشتر افزایش نمیافت، بلکه حرکت باید بسوی موازی سازی پردازنده ها سوق میافت. این بود که این مساله ی چند هسته ای بودن پردازنده ها بود که بر سر زبان ها افتاد! از طرف دیگر، AMD با معرفی اولین پردازنده ی تجاری 64 بیتی، یک تحول دیگر در این زمینه اجرا کرد و از سوی دیگر، سازنده ها برای بسط بیشتر عملکرد، بسوی کمتر کردن BottleNeck های محاسباتی نیز روی آوردند و اینگونه بود که حافظه های بسیار سریعCache رشد قابل ملاحظه ای از نظر اندازه ظرفیت پیدا کردند و مفهوم Hierarchy وارد سلسله مراتب این حافظه گشت و L2 ها حجیم تر از قبل شدند بطوری که پردازنده های معمول دوهسته ای حال حاضر، دارای Cache L2 ۳و۴ مگابایتی شده اند..
اما در ورای تمام این هیاهوها، تشنگی غیر قابل فروکش طرفداران بازی، موجب پیشرفت های شگرف در زمینه ی کارت های گرافیکی میشود. شما در نظر بگیرید که یک کارت گرافیکی محبوب و قوی، چه زود و بیرحمانه کهنه و از میدان بدر میشود! روحیه و ساختار نرم افزار های بازی، همواره کفه ترازو را بسمت پردازنده ها (GPU) هایی سنگین میکرد که قابلیت پردازش شدید موازی، برای دست و پنجه نرم کردن با Resolution های روزبروز ریز تر و پیچیده تر و طبیعی تر، سنگین میکرد. و این حرکت کاملا در راستای قانون مور در حرکت است و بدلیل ذات موازی و کمتر پیچیده بازی ها، خواهد بود!
در این میان، ایده ای بسیار بکر و زیبا در دنیای سایبر متولد شد: General Purpose GPU ها.
این تفکر سعی در انتقال بار سنگین پردازش موازی در شبیه سازی های علمی علوم مختلف، از جمله مکانیک نیوتونی، دینامیک سیالات، مکانیک کوانتومی، پروتیین ها و کلا هر محاسبات ‹حجیمی‹ که بر اساس آرایه ها و ماتریس های بسیار بزرگ شبیه سازی شده اند را، بر روی ساختار بشدت موازی GPU ها منتقل کنند. قابل ذکر است که یک RV770 مربوط به AMD Radeon HD4870، دارای 800 هسته ی محاسباتی SIMD (Single Instruction-Multiple Data)، با سرعت Clock حدود 750MHz میباشد!
این اساس ایده ی پیاده سازی آرشیتکت CUDA از Nvidia بر روی کارت های گرافیکی اش است. Compute Unified Device Architecture بر هدف متمرکز کردن و استفاده ی بهینه تر از مخازن محاسباتی موجود در یک کامپیوتر نشانه گیری کرده:
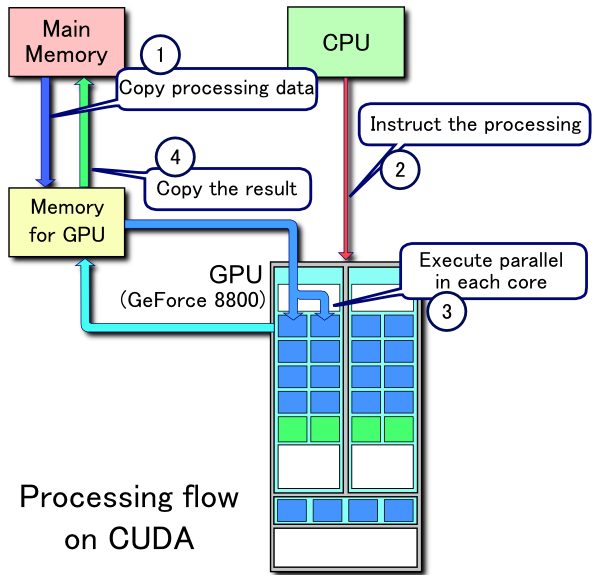
برای درک عمق بهبود محاسباتی این پدیده، بهتر است به این مقایسه توجه کنید. یک پردازنده ی بسیار گرانقیمت ۴ هسته ای و ۶۵ نانومیلیمتری اینتل با سرعت 3.2 GHz، دارای توان محاسباتی ۶۴ بیتی حداکثر حدود ۴۸ GFLOPS است، در حالیکه یک کارت گرافیکی سطح متوسط Nvidia GeForce 8600M GT که در لپ تاپ های پارسال بکار گرفته میشد (از جمله کامپیوتر من!)، دارای توان محاسباتی خارق العاده ی ۳۲ بیتی 91.2 GFOPLS میباشد!! این مقدار اختلاف، یقینا خیره کننده و برندست، با اینکه در یک پردازش ۶۴ بیتی، کارت گرافیکی ما به حدود سرعت CPU بسیار سطح بالای مان نزول میکند!
اینجا بود که AMD و Nvidia به تولید تجاری سری های FireStream و Tesla دست زدند که کارت گرافیکی هایی هستند بدون هیچ خروجی تصویر و مونیتور! یعنی در اصطلاح صحیح، در ردیف co-processor ها قرار گرفته اند.

کار بجایی پیش رفته که حتی Nvidia دست به تولید Node ها و سرور هایی بر مبنای زده که هر Node در برگیرنده ی ۴ هسته ی گرافیکی است. بعنوان مثال، S1070 1U، مجهز به ۴ GPUی 240 هسته ای C1060 میباشد که در مجموع به رقم خیره کننده ی ۹۶۰ هسته برای هر Node که هرکدام یک پردازنده ی SIMP با 602MHz سرعت Clock هسته اند میرسیم!

این عکس به گفته ی Nvidia، اولین سوپر کامپیوتر شخصی دنیا، بنام Quadro Plex و با حدود ۳۰۰۰ دلار قیمت است!

نکته بسیار جالب در مورد این VCS (Visual Computing System)چهار هسته ای با 16GB رم اینه که از طریث یک کابل به اسلات PCIe مادربرد PC شما وصل میشود و شما یک منبع 4TFOPLSی در کنار Case خود خواهید داشت!

